Via Jeremy Freese, a paper by Alan Gerber and Neil Malhotra called “Can political science literatures be believed? A study of publication bias in the APSR and the AJPS.” Here’s the main finding.
When you run a bog-standard regression, you typically want to know how much a change in some variable _x_ — usually a number of such _x_ variables — is associated with a change in _y_, some outcome variable of interest. When you run the regression on your data, you get a coefficient for each _x_ telling you how much a one-unit change in that _x_ changes the value of _y_. But you also want to know whether that estimate is worth paying attention to. So you calculate a statistic — a p-value — that tells you, roughly, whether the coefficient you got is relatively unexpected or unusual. How unexpected is unexpected enough to be interesting? This is a matter of convention. There is an established threshold below which you are not typically entitled to say the result is “statistically significant.” The subtleties of interpreting p-values need not detain us here. The point is that for good or bad there’s a conventional threshold.
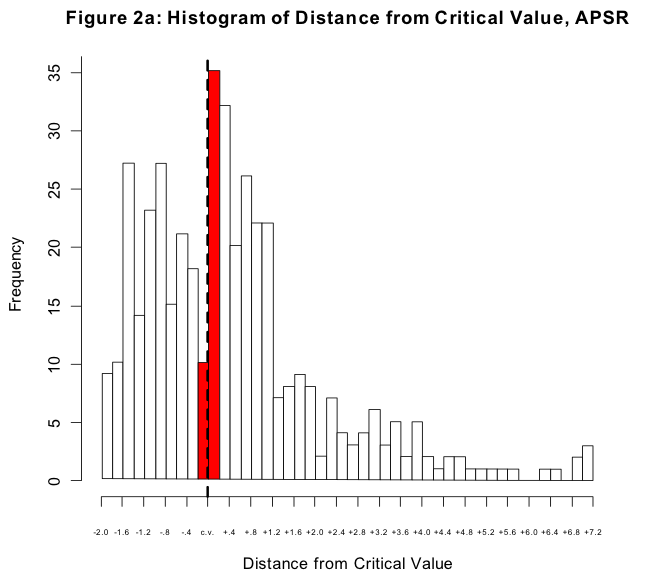
Now, if you write a paper describing negative results — a model where nothing is significant — then you may have a hard time getting it published. In the absence of some specific controversy, negative results are boring. For the same reason, though, if your results _just barely_ cross the threshold of conventional significance, they may stand a disproportionately better chance of getting published than an otherwise quite similar paper where the results just _failed_ to make the threshold. And this is what the graph above shows, for papers published in the _American Political Science Review_. It’s a histogram of p-values for coefficients in regressions reported in the journal. The dashed line is the conventional threshold for significance. The tall red bar to the right of the dashed line is the number of coefficients that just made it over the threshold, while the short red bar is the number of coefficients that just failed to do so. If there were no bias in the publication process, the shape of the histogram would approximate the right-hand side of a bell curve. The gap between the big and the small red bars is a consequence of two things: the unwillingness of journals to report negative results, and the efforts of authors to search for (and write up) results that cross the conventional threshold.
Political Science — or social science in general — is not especially to blame here. There’s an ongoing controversy in clinical trials of drugs, where pharmaceutical companies are known to conduct a large number of separate trials for a new product, and then publish only the ones that yielded significant results. (An important fact about statistics is that everything has a distribution, including expected results from multiple clinical trials: if you try often enough you will get the result you want just by chance.) If there are enough published trials, techniques like meta-analysis can help reveal the number of “missing” trials — the ones that were done but not published, or just not done at all.
This all reminds me of an old joke, a shaggy dog story about a man who gets thrown into a jail cell with a long-term occupant and then begins a series of attempts to escape, each by some different method. He fails every time, getting captured and thrown back in the cell. The older prisoner looks at him silently after each failure. Finally, after six or seven attempts, the man loses his patience with the old prisoner and says “Well, couldn’t you help me a little?” “Oh,” says the old guy, “I’ve tried all the ways you thought of — they don’t work.” “Well why the hell didn’t you tell me?!” shouts the man. “Who reports negative results?” says the old prisoner.
{ 2 trackbacks }
{ 25 comments }
Daniel Nexon 09.19.06 at 9:54 pm
This is a very serious problem for any field that considers itself to be developing cumulative knowledge. The shaggy dog story illustrates why quite well.
Mill 09.19.06 at 11:26 pm
If only there were some sort of interconnected network of devices capable of storing information — “artificial brains”, if you will — where space constraints were rendered negligible and the need to justify printing and distribution fees with exciting information were eliminated! If such a thing did exist, why, anyone could publish anything they want!
Scholars could even band together to create vast repositories of information that, while not sensational enough to justify ink-and-paper printing, might nevertheless be useful to future researchers. (Peer review and editorial oversight could be handled by Zeta clones, postgrads, etc. I dismiss these concerns with a wave of my hand, like so. There might possibly be some value even without the same level of peer review.)
Where printed versions were absolutely necessary, they could be produced in industrial centers and distributed by Zeppelin.
(Seriously, very clear layman’s explanation of the issues involved and the significance of that graph. Thank you.)
Paul Orwin 09.20.06 at 12:41 am
Let me just play devil’s advocate for a minute.
Should you expect the distribution to be different?
Surely we all agree that negative results are rarely valuable for publication-it’s only the rare event where a set of studies (in any field) results in conclusively showing that a relationship between variables does not exist. After all, few people set out to do such a study; the exception is when someone has claimed a relationship you don’t believe exists, and there is some value to showing it’s absence. Additionally, the burden on such a study is correspondingly higher-you aren’t just saying “I looked and found nothing†but rather “I looked, and where X found something, I’ve shown that it was really nothing”. This is self-evidently going to carry a higher evidentiary burden (falling just short of significance would indicate bad technique, rather than disproof).
On the other hand, lots of important positive results are extracted from very large data sets or very complex procedures (again, in all fields). Finding small effects is important, too.
Clearly the effect described is one of publication bias (as you say, correctly). I’d suggest, however, that this in itself does not indicate poor pub standards – Pick an ultra rigorous, highly respected journal (Science, Nature, Cell, etc etc) in the sciences, and run the same analysis. I expect you will get the same result.
In some sense, I think this is a poor definition of bias. After all, isn’t the point of statistical significance to determine the presence or absence of an effect? Given the reality of the publishing world (and, incidentally, agreeing with the comment above) doesn’t it make sense to only publish results showing a statistically significant effect?
I understand that people would like to see data showing negative results (so they can better utilize their time, energy and $$), and I know a “Journal of Negative Results†has been proposed (probably at least once on this site).
The subtitle “can we trust the literature†on the paper cited seems hyperbolic at the most charitable. It actually seems odd to me that this paper was published, given how unsurprising and relatively useless the finding is.
Daniel 09.20.06 at 1:19 am
Paul – Kieran’s study is measuring something a little bit different from yer normal publication bias (which can kindasorta be corrected for; the metastudy literature has a few methods for estimating the number of unpublished studies that you would have to assume existed in order for the published literature to be an artifact of bias). The problem here is the short red bar, forming the “notch” in p-values at the (utterly arbitrary) 5% level. This strongly suggests that there has been model-dredging; that a lot of borderline models have been effed around with until their standard errors pass a 5% t-test. This undermines the validity of the t-test, because it makes it clear that the t-ratio isn’t actually draw from an underlying t-distribution – it’s a draw from a distribution of numbers that has a lower bound of 1.96, because the model is messed around with until a specification that gives “significant” results is found.
In the medical, etc, etc literature you will get a lot of publication bias, but I don’t think you will get this specific and highly pathological form because the fetishisation of the 5% significance level is a much more prevalent disease in social sciences (though it is being exported into “evidence based medicine” at an alarming rate).
Paul Orwin 09.20.06 at 1:31 am
I see the point, and I don’t dispute the idea that publication bias is present. I can’t obviously speak to the validity of social science models, since I am utterly ignorant (here’s where the obligatory “never stopped you before: ed” line goes). I think you are mistaken about the prevalence of this sort of “fetishization” of the p=0.05 line. I suspect that it is common for scientists doing laboratory studies to essentially work toward the goal of this significance value in their tests. However, it seems to me that if the phrase “statistically significant” means something (and it does, concretely) then we should accept it’s meaning, absent evidence that the statistical test is invalid. It doesn’t seem to me that this paper presents any such evidence.
Daniel 09.20.06 at 2:42 am
but isn’t the very existence of the “notch and spike” evidence that the test is indeed invalid. I wrote something on my own blog about this, a million years ago here.
The problem is that the t-test for significance implicitly assumes that one is making a random draw from a t-distribution. If, on the other hand, the experimenter iteratively rejigs the model until it passes the 5% significance test (or in other words, until the t-ratio is greater than 1.96), then the draw is definitely not from a t-distribution; it’s from some other unknown distribution which is much more likely to have a ratio greater than 1.96. So the test for significance can’t be given its normal interpretation because the data-mining means that the assumptions aren’t satisfied. And the notch-and-spike is exactly what you’d expect to see if this practice was very prevalent and since ex hypothesi nobody owns up when they do this, you can’t tell of any specific paper in the social sciences literature whether their coefficients pass the significance tests because the model genuinely has a significant effect or because they were data-dredged[1] to do so.
[1] I prefer the term “data-dredging” to “data mining” in this context because there are non-pejorative senses of “data mining”. Also a miner sometimes strikes gold but a dredger only ever stirs up mud.
BrendanH 09.20.06 at 5:49 am
There is a lot more on this theme. See Why Most Published Research Findings are False, which at least has a great title.
We shouldn’t get too hung up on single papers, though. Findings only become important when they crop up repeatedly, from different researchers, using different data, different methods. And let’s not forget theory.
dearieme 09.20.06 at 6:59 am
I wonder how often the rejection of a few outlier points in a dataset leads to the happy result of crossing that threshold? In an experimental science, one can return to the lab and try to repeat the experiment with the outlier result: if it proves not to be reproducible, one can reject it with a reasonably clear conscience. What does one do in the social sciences?
Daniel 09.20.06 at 7:13 am
all sorts of things, but to be honest a clear conscience is not at all the likely outcome.
btw, just picked this up:
An important fact about statistics is that everything has a distribution
I swear you put these in just to annoy me Kieran! I suppose that everything that can be tabulated has an empirical distribution (the table), but this statement is ambiguous in a quite dangerous way between that truism and the belief that all stochastic phenomena are draws from an underlying distribution. Yes I am about to start ranting about nonergodicity again, sorry very much.
Rich B. 09.20.06 at 8:10 am
but isn’t the very existence of the “notch and spike†evidence that the test is indeed invalid. . . .The problem is that the t-test for significance implicitly assumes that one is making a random draw from a t-distribution. If, on the other hand, the experimenter iteratively rejigs the model until it passes the 5% significance test (or in other words, until the t-ratio is greater than 1.96), then the draw is definitely not from a t-distribution;
I don’t see this. If you read the chart in Hebrew or Arabic (right to left), there doesn’t appear to be a “spike” at all — just a gentle upward slope.
If there were a “re-jigging” with results, one would expect to see a large red bar in contrast to the white bar to its right. The fact that the large red bar isn’t much higher than the white bar, but is, rather, much higher than the red bar to the its left indicates to me that there are lots of unpublished studies (publication bias), not that there is anything less credible or “rejigged” about the studies that were actually published.
eweininger 09.20.06 at 8:32 am
What does one do in the social sciences?
As long as the data isn’t proprietry, anyone who’s interested can go back and replicate(*) the analysis, evaluating the impact of including or excluding particular cases in the process. The ability to do this is buttressed by informal norms in favor of making one’s computer code available to anyone who asks nicely. Should an important result hinge on a debatable decision to include or exclude cases, then this can of course be publicized to the relevant community of researchers.
*Intended in the non-legally-actionable sense only.
eweininger 09.20.06 at 8:37 am
Rich b–the issue is not the really high bar that leans against the dotted line on its left; its the low bar that caresses the dotted line on its right. The frequency of p=.06, p=.07, p=.08, etc are far below their expectation values.
eweininger 09.20.06 at 8:39 am
Of course, in my effort to clarify, I reversed left and right in the above comment. Good thing I don’t teach today.
bethany 09.20.06 at 8:59 am
daniel, for “yer” you get 5 style points, for confusing Kieran’s word “statistics” with your concern for empirical measurements (the stuff that one would feed into statistical models), you lose 2. I let you keep 3, so you can keep playing because I think your underlying gripe is correct in that usually measurement and statistics go together and when people screw it up they cause harm–as in Kieran’s complain about death rates. I’d just say that in this case, you’re wrong.
leederick 09.20.06 at 9:03 am
How terrible is it that about 5% of results are bumped from one side of an arbitrary line to the other? Instead of an arbitrary 5% significance level, you’re working with a de facto arbitrary 6%ish significance level. So long as you all cheat consistently, aren’t you in the same position as you would be if you’d put your arbitrary line in a different place?
Daniel 09.20.06 at 9:08 am
leederick: but the trouble is that you don’t know whether the cheating is done consistently. You don’t even know whether the propensity to cheat is uncorrelated to the conclusions of the paper and in most cases you might suspect that it wasn’t.
JL 09.20.06 at 9:10 am
Many years ago, when I was in graduate school, one of my professors, an experimental social psychologist, proposed that journals evaluate papers solely on the basis of research design. Researchers would submit all the preliminary stuff including the design but not the results. If the journal accepted the paper, researchers would then provide the data regardless of p values. I’m not sure how this method would work with non-experimental research.
Tim McG 09.20.06 at 9:44 am
Don’t political scientists look more sceptically at the just barely significant results? Especially if they claim importance? Or is the real dirty secret of all academia that everyone just reads the abstracts?
I’m inclined to be Very Sceptical that mischief like this will compound itself into larger error; rather, someone may attempt to build further on barely-significant results and find nothing.
Paul Orwin 09.20.06 at 10:51 am
I see your point Daniel (and Kieran), and yet, I can’t quite let go of this issue. I think the problem is more generally the opacity of highly specialized research (in any field, but I suppose in this context more in the social sciences) that precludes reviewers from critically analyzing methods. So, you get a paper to review, and it says something like “the data were analyzed using the such-and-such procedures modified to suit the unique nature of our data set”, and that leaves you with the questions Daniel is asking (i.e., what pts did they leave out to get that sig value to 0.05).
So, an alternative hypothesis is that rather than “tweaking” the model (to be charitable), instead people take large data sets, test lots of different models till they find one that gives them p
elliottg 09.20.06 at 3:33 pm
My favorite is the multiple regression against more than 10 variables that reports 1 is significant.
rcriii 09.20.06 at 4:07 pm
I prefer the term “data-dredging†to “data mining†in this context because there are non-pejorative senses of “data miningâ€. Also a miner sometimes strikes gold but a dredger only ever stirs up mud.
On the contrary, David, dredgers dig plenty of stuff besides mud. Plus dredgers usually get paid for everything they dig up, while miners often end up with fools-gold.
dipnut 09.20.06 at 4:20 pm
What? No tits?
vivian 09.20.06 at 9:13 pm
In political science, a worse problem is the paper that fits lines to the outliers, not the paper that ditches them, usually with some discussion. We tend to have lots of problems with not-quite-homogeneous cases aggregated with more-or-less justification, to get a population large enough to generalize about. When they don’t quite fit the hypothesized relationship, it often is that they don’t really belong. And if you’re professionally concerned, you will read the discussion of which cases are omitted, and why, and rant about it in another article, or student lounge, or whatever.
But it’s kind of scary to disagree with Daniel, and so forth. Just thought I’d say. Also, it’s in a journal that has mandatory publication of replication data and code, so anyone who cares, follow the link and play around for yourselves.
jprime271 09.21.06 at 6:55 pm
Great post! And great article! Between this and his GOTV stuff, Alan Gerber is one of the best scientists ever to recently set foot into social science. I hope this piece gets read widely! Negative results are the vitally important to moving scientific debates forward. I’ve had several papers rejected, partly based on the complaint that they reported negative results. How else does one disprove theories if one cannot publish negative results?
derek 09.24.06 at 2:59 pm
Paul, it is not actually true that negative results aren’t valuable: they are. The trouble is that they aren’t sexy. My lab tutors hammered it into me that to only report your positive results is only slightly short of fraud.
They were probably being polite to say “slightly short”. In fact it is a known scam to send stock predictions or racing tips to a number of potential marks, then use the credibility you gain with the minority of them to fleece said marks. After all, they don’t know about the other potential victims you sent your (wrong) predictions to, who were not as impressed.
Comments on this entry are closed.